
파이썬 기초편(1) - 리스트 본문
● print함수의 복습과 확장
print함수는 출력이 끝내면 줄을 바꿔버린다. 줄을 바꾸지 않고 이어서 출력이 되도록 하려면 end=''옵션에 추가하면 된다.
for i in [1, 2, 3]:
print(i)
# 1
# 2
# 3
for i in [1, 2, 3, 4]:
print(i, end='__')
# 1__2__3__4__
● 리스트형 데이터
for i in [2, 4, 6]:
pass # pass라고 입력하면 아무 일도 하지 않는 for루프가 만들어진다.▶ [1, 2, 3]은 정수 1, 2, 3을 묶어 놓은 '리스트형(list type) 데이터'이다.
▶ 리스트는 여러 개의 값을 묶는데 사용된다. ex) [1, 3.14, "Hi"]
▶ 리스트를 변수에 담는것도 가능하며, 리스트 안에 리스트를 담는 것도 가능하다. ex) num=[1,2,3], [1, 2, [3, 4]]
● 리스트형 데이터의 연산: 인덱싱 연산
[1, 2, 3] + [4, 5] # [1, 2, 3, 4, 5] 두 리스트를 합한 결과를 반환
[1, 2, 3 * 2 # [1, 2, 3, 1, 2, 3] 리스트의 내용을 두 배 늘린 결과를 반환▶ [ ] 인덱싱(indexing) 연산
▶ [ : ] 슬라이싱(slicing) 연산
'인덱싱 연산'이란 리스트에 담겨 있는 값들 중 하나를 참조하는 연산이다. 그리고 인덱싱 연산에서 리스트의 첫번째 값을 가리킬 때는 1이 아니라 0을 사용한다. 그리고 두번째 값을 가리킬때는 2가 아닌 1을 사용한다. 이렇듯 인덱싱 연산에서 0은 맨 앞을 의미한다.
또한 리스트의 인덱스 값이 양수이면 오른쪽으로, 음수이면 그 반대로 접근을 하게 된다. 인덱스 값이 -이면 첫번째 값에 접근하듯이, 인덱스 값이 -1이면 마지막 값에 접근하게 된다.
st = [1, 2, 3, 4, 5]
print(st[-1], st[-2], st[-3], st[-4], st[-5])
# 5 4 3 2 1
# st[-1] = 5
# st[-5] = 1
● 리스트형 데이터의 연산: 슬라이싱 연산
st = [1,2,3,4,5,6,7,8,9]
mt = st[2:6]
print(mt) # [3, 4, 5, 6]'슬라이싱 연산'은 리스트에 속한 값들 중 하나 이상의 값을 묶어서 이들을 대상으로 하는 연산이다. 주의해야 할 부분은 st1[2:5] 부분이 의미하는 것은 st1[2] ~ st1[4] 까지 이다(st[2], st[3], st[4]). 다음과 같이 해석해야 한다.
"st1[2]의 값 부터 st1[5] 바로 앞의 값 까지..."
st = [1, 2, 3, 4, 5]
st[2:4] = [0] # ※넣는 값이 iterable 객체여야 한다.※
print(st) # [1, 2, 0, 5], 슬라이싱 범위의 값이 넣는 값으로 대체된다.슬라이싱 연산의 '값의 수정'은 '부분 교체'로 볼 수 있다. 부분 교체를 할 때는 값의 개수가 같을 필요는 없다. 더 많아도 되고 적어도 된다.
● 슬라이싱 연산에서 생략 가능한 부분
st = [1, 2, 3, 4, 5, 6]
st[0:3] = [0, 0, 0] # [0, 0, 0, 4, 5, 6]
st[:3] = [0, 0, 0] # [0, 0, 0, 4, 5, 6]
st[3:] = [0, 0, 0] # [1, 2, 3, 0, 0, 0]
st[:] = [0, 0] # [0, 0] 리스트 전체를 [0, 0]으로 교체
● 리스트에서 두 칸씩 뛰면서 저장된 값들 꺼내기
st = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
mt = st[0:9:2] # [1, 3, 5, 7, 9]
nt = st[0:9:3] # [1, 4, 7]
● string형 데이터: 문자열
'문자열'은 그 자체로 문자들을 묶어 놓은 데이터이다. type 함수 호출결과로 출력된 <class 'str'>은 전달된 값이 '스트링형 데이터'임을 의미한다.('스트링형 데이터'라는 표현보다 '문자열'이라는 표현을 많이 쓴다)
문자열은 리스트와 유사하게 덧셈, 곱셈, 인덱싱, 슬라이싱 연산이 가능하다. 단, 리스트와 달리 문자열은 그 내용을 바꾸지 못한다(매우 중요한 사실이다). 문자열의 일부를 바꾸는 연산을 하면 오류가 발생한다.
# 덧셈 연산
[1, 2] + [3, 4] # [1, 2, 3, 4]
"Hello" + "Everybody" # HelloEverybody
# 곱셈 연산
[1, 2] * 3 # [1, 2, 1, 2, 1, 2]
"AZ" * 3 # AZAZAZ
# 인덱싱 연산
st = [1, 2, 3, 4, 5]
st[2] # 3
str = "SIMPLE"
str[2] # M
# 슬라이싱 연산
st = [1, 2, 3, 4, 5, 6, 7]
st[2:5] # [3, 4, 5]
str = "SIMPLEST"
sr[2:5] # MPL
● 리스트와 for 루프 그리고 문자열과 for 루프
for i in [1, 2, 3]:
print(i, end=' ') # 1 2 3
for i in "Happy":
print(i, end=' ') # H a p p y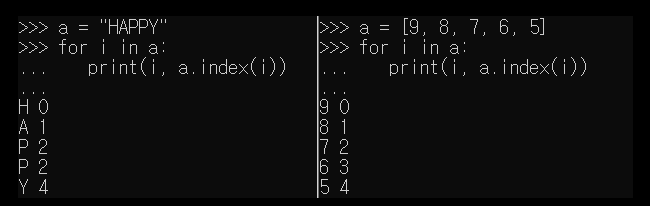
● 리스트와 문자열을 인자로 전달받는 함수 len
st = [1, 2, 3]
len(st) # 3
sr = "HAHAHA~"
len(sr) # 7
● 리스트와 문자열을 인자로 전달하고 반환하기

◆ 리스트와 문자열 함수들
● 리스트와 함수들
st = [1, 2, 3, 4, 9, 8]
len(st) # 6
min(st) # 1
max(st) # 9
st.remove(2) # 2를 찾아서 삭제한다
st # [1, 3, 4, 9, 8]위의 예제에서는 len함수나 max함수와는 다르게 변수이름 옆에 점을 찍어서 remove함수를 호출했다. 사실 리스트는 '값'만 존재하는 게 아니라 '함수'도 존재한다. 리스트는 다음과 같이 채워져있다.

위와 같이 데이터(값)와 함수가 묶여서 존재하는 덩어리를 가리켜 '객체(object)'라고 한다. 그러니까 리스트는 사실 '객체'이다. "리스트는 함수와 데이터가 함께 존재하는 객체이다." 그리고 객체 안에 존재하는 함수를 호출하는 방법은 변수명.함수
와 같은 방식으로 호출한다.
리스트 객체에는 다음과 같은 함수들이 존재한다.
s.append(x) # 리스트 s의 끝에 x를 추가
s.extend(t) # 리스트 s의 끝에 또 다른 리스트 t를 추가
s.clear() # 리스트 s의 내용물 전부 삭제
s.insert(i, x) # s[i]에 x를 저장, 기존의 값들은 한 칸씩 뒤로 넘어감
s.pop(i) # s[i]를 반환 및 삭제, pop()은 위치를 지정
s.remove(x) # s에서 가장 앞에 등장하는 x를 하나만 삭제, remove()는 값을 지정
s.count(x) # s에 등장하는 x의 개수를 반환
s.index(x) # s에 처음 등장하는 x의 인덱스 값 반환함수는 두 가지의 유형의 함수가 존재한다
- 객체 안에 있는 함수
- 객체 밖에 있는 함수
"객체 안에 있는 함수"들은 해당 객체만을 대상으로 동작한다는 특징이 있다. > 객체 안에 존재하는 함수들은 해당 객체에 특화되어 있다. 반면 "객체 밖에 있는 함수"들은 특정 객체 또는 값에 특화되어 있지 않다. 다양한 값이나 객체들을 대상으로 동작한다.
함수를 "객체 밖에 있는 함수"의 형태로 만들었다면, 이는 다음과 같은 이유가 있는 것이다.
- 둘 이상의 다양한 종류의 값을 대상으로 동작하는 함수를 만들고자 하였다.
- 또는 만들기 편하고 사용하기도 편해서 선택하였다.
반면 함수를 "객체 안에 있는 함수"의 형태로 만들었다면 다음과 같은 이유가 있을 것이다.
- 해당 객체에 특화된 형태로 함수를 만들고자 하였다.
● 문자열과 함수들
문자열도 리스트와 마찬가지로 "객체(object)"다. 따라서 문자열 객체 안에도 다음 함수들이 존재한다.
s.count(sub) # 문자열 s에 sub가 등장하는 횟수 반환
s.lower() # s의 내용을 전부 소문자로 바꾼 문자열 반환
s.upper() # s의 내용을 전부 대문자로 바꾼 문자열 반환
s.lstrip() # s의 앞에 위치한 공백 모두 제거한 문자열 반환
s.rstrip() # s의 뒤에 위치한 공백 모두 제거한 문자열 반환
s.strip() # s의 앞과 뒤에 위치한 공백 다 제거한 문자열 반환
s.replace(old, new) # s의 old를 전부 new로 교체한 문자열 반환
s.split() # s를 ()안의 값을 기준으로 나눠서 "리스트에 담아서" 반환리스트에서는 값을 수정했지만 문자열은 수정이 불가능한 타입이다. 때문에 수정된 문자열이 아닌 새로운 문자열을 반환한다.
● 문자열의 탐색 관련 함수들
s.find(sub) # 문자열 s에 sub가 있으면 그 위치의 인덱스값, 업으면 -1 반환
s.rfind(sub) # s.find는 앞에서부터 찾는 반면, s.rfind는 뒤에서부터 찾는다. 차이점은 탐색의 방향이다
● 문자열의 일부로 포함이 되는 이스케이프 문자
\n # 줄 바꿈
\t # 탭
\' # 작은따옴표 출력 ex)'제가 마음속으로 그랬습니다. \'이건 아니야.\'라고 말이죠.'
\" # 큰따옴표 출력 ex) "제가 소리 질렀습니다. \"이건 아니야!\"라고 말이죠."
● 함수가 아닌 del 명령
st = [1, 2, 3, 4, 5, 6]
del st[:] # 리스트에 저장된 값을 모두 삭제, 빈 리스트만 남는다
del st[3:] # st[3]부터 모두 값 삭제
del st[0] # st[0] 값을 삭제
del st # 리스트 자체를 통째로 삭제!
'Programming > python' 카테고리의 다른 글
| 파이썬 기초편(1) - 클래스와 객체 (0) | 2022.06.14 |
|---|---|
| 파이썬 기초편(1) - 딕셔너리(Dictionary) (0) | 2022.06.14 |
| 파이썬 기초편(1) - '모듈의 이해' 그리고 '수학 모듈' 이용하기 (0) | 2022.06.12 |
| 파이썬 기초편(1) - 튜플(tuple)과 레인지(range) (0) | 2022.06.10 |
| 파이썬 기초편(1) (0) | 2022.05.19 |


